I sometimes feel dumb when it comes to Machine Learning and AI. I was taught some basic concepts back in college and took some online courses but keep forgetting stuff. Here I’ll be experimenting as I learn and keep sharing it to revise my concepts and maybe help someone along the way. If you can correct me, that’ll be a big plus too !
Let’s say we want to predict a value based on some other values. These values can have any relation, logic or formulae which is not known to us. Look at this data below
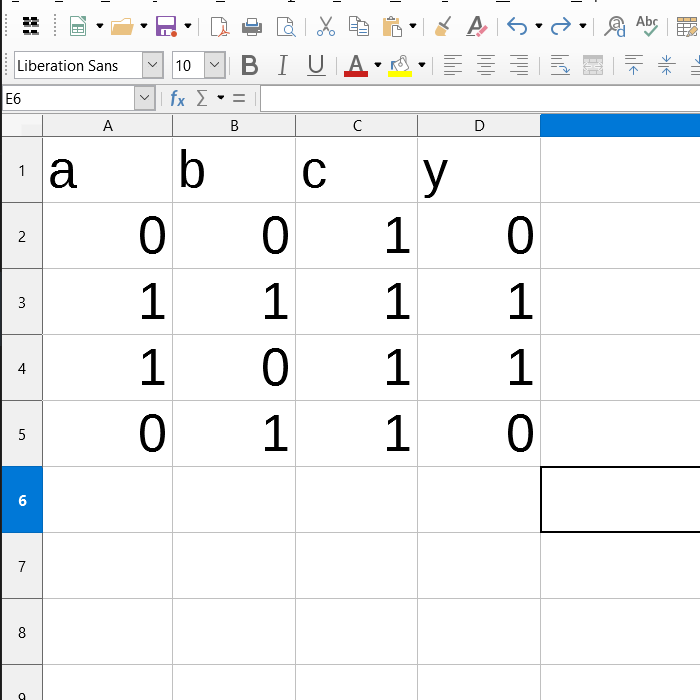
This is a very small data set of 4 records. We have 3 features to learn from namely a, b & c. We wish to find the value of y given these three. Now it may seem like a simple problem, for the above data. Some can even readily look at it and make a guess what formula to use. This is a very simple data set with very few records, more complex behaviors can emerge if there is lots of data. Lets say we don’t know that behaviors and just want use the machine to predict it for us.
Create a Kaggle notebook to work with our data, here. This will give us a ready environment to start working instead of installing all the languages, libraries and tools on our system.
Add this data (Excel CSV file) set to your notebook or create your own and upload it. Import pandas to work with the file.
import pandas as pd #to work with CSVs
mydata_path = '../input/simple.csv' #import file
mydata = pd.read_csv(mydata_path) #read the file
You can review your first few lines of data.
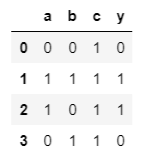
mydata.head() #first few lines
Select the features or variables you want your machine learning model to use for prediction. Set the output you want your machine to learn from. It will look at the features and then look at the output and try to create a pattern for prediction.
#The model will look and a, b & c
features=['a','b','c']
X = mydata[features]
#The model will then look at the output y
y = mydata.y
Now we import the sklearn library to work with machine learning models. This gives us various machine learning models to work with without having to write our own and learn all the complex math right from start. We will use a tool called Decision Tree, it lets us create a tree like structure of decisions and their possible consequences. Our model will use this tree to predict the consequences that yield the output that closely matched behavior exhibited between our features a, b & c and output y. We will fit a decision tree as per our data.
from sklearn.tree import DecisionTreeRegressor #Decision tree model ready code
my_model = DecisionTreeRegressor() # initialize an empty model
my_model.fit(X, y) #make a decision tree that fits our data
In ideal case we should always test our model on new data, and see if it’s accurate enough. But since we have a very small data set we will just test on the same data.
#We create 5 test conditions
case_one =[1,1,1]
case_two =[1,0,1]
case_three =[0,0,0]
case_four =[1,0,0]
case_five =[1,0,1]
y_test=[case_one,case_two,case_three,case_four,case_five]
print(my_model.predict(y_test))
#OUTPUT for 5 predictions
#[1. 1. 0. 1. 1.]
If you cross check with out data set you can verify that the predictions are correct, but we haven’t predicted something new. This was already learned earlier. Let’s try predicting a new set of values of a, b & c.
new_case =[0,0,1]
y_test=[new_case]
print(my_model.predict(y_test))
#OUTPUT
[0.]
So, our model seems to work ! Now to be really sure we will need lots of data for training & testing. But for our purposes I can say that this works. Why ? Like I said you can predict yourself what the model would’ve learned. If you look closely, you can see the formula learned is something like…
y=a+bX0+cX0
i.e the output y matches exactly with the feature a, it does not depend on b or c. But again this is a very small data set and this prediction holds only true in this case. You cannot always look at 4 records and predict this type of behavior for large datasets. So there you have your simplest machine learning model ! Link to Kaggle notebook. Link to code. Link to data set.
Will add more… thanks for checking out !
